Salesforce Data Cloud offers a lot of functionalities in terms of data aggregation, transformation, unification, segmentation, and activation. But, using these features, we should be careful regarding service data usage billed with so-called Credits. How it works?
Data Cloud billing could be tricky, especially with credit-burning features like data streaming and profile unification. With a higher amount of data (hundreds of thousands of records and more), you should be more careful when using Data Cloud capabilities. Especially if there is no easy way to check how much of them you still have.
Data Cloud Licenses
Data Cloud Licensing is not so clear in pricing and features as other tools e.g. Sales/Service/Marketing Cloud. From the official information available on the Salesforce.com site we can evaluate that there are two common licenses - free Data Cloud Provisioning and paid Data Cloud Starter license. The second one appears in different types – Data Cloud for Marketing Starter, Data Cloud for Tableau Starter, and Data Cloud for Health Starter.
Salesforce Data Cloud is officially free to use with its Data Cloud Provisioning (also called Data Cloud Everywhere) package, containing 250,000 Data Services credits per year, 1 Data Cloud Admin Account, 100 Data Cloud User Accounts, and 5 integration users, plus 1 TB of storage for users with Salesforce Enterprise and Unlimited editions. Unlimited Plus edition gets 2,500,000 credits per year. This package is a nice entry to the Data Cloud world, especially with 1 TB of storage that we can use. It is also a good opportunity to check what Data Cloud could do. Remember that if you have a longer contract, for example for 3 years, the number of credits will be multiplied (e.g. 250,000 x 3 = 750,000) and you will have access to the entire pool immediately.
Data Cloud Starter for Marketing is probably the most common type of license. Usually sold with Marketing Cloud, contains 10M credits, 5TB of storage, 1 Data Cloud Admin Account, 100 Data Cloud User Accounts, and 5 integration users.
Data Cloud Starter for Tableau looks similar to the Marketing one. 10M credits, 5 TB of storage, but there are no possible add-ons such as segmentation, data spaces, or ad audiences.
Data Cloud Starter for Health looks different from the two previous licenses. It is treated not as a separate Cloud license, but as an add-on to the Health Cloud. There are also no starter credits or storage - you have to buy it separately, the same as Unified Health Scoring, which is a Unified Profiles variation for your patients.
Marketing Cloud Growth is a new addition to the Salesforce portfolio. The license provides Data Cloud instance with 1 TB of space, limited 10,000 unified profiles, 240,000 Data Services credits and 10,000 Segment and Activation credits. The fun fact is that to use Marketing Cloud Growth license you should have Service/Sales or other Salesforce license (which provides free Data Cloud), so there could be an option to merge the free tier and Growth Edition credits pool (I hope so…).
Data Cloud for Commerce is the newest license in the Salesforce inventory. But there is not so much information about it. You can find the mention of this license in the Release Notes and Trailhead, but nothing more.
Data Cloud Add-ons
Data Spaces - if you want to create some kind of “internal environments”, for example for each of your brands, you have to purchase the Data Spaces Add-On for your Data Cloud instance. The basic cost is 60,000$ per data space per year.
Data Storage – if you exceed the basic storage (1 TB or 5 TB) in your Data Cloud instance, you have to buy an additional Data Storage Add-On. The basic cost is 23$ per 1 TB of additional data storage per month.
Data Services – if you need more Services Credits, you have to purchase the Data Services Add-On, containing 100,000 Services Credits. The basic cost is 500$ per 100,000 Service Credits.
Ad Audiences – if you want to activate the segments to advertising platforms like Meta, Amazon Ads, and Google Ads, you have to purchase the Ad Audiences Add-On for your Data Cloud instance. The basic cost is 2400$ per audience per year.
Sub-Second Real-Time Service Usage - if you want to use Real-Time Identity Resolution, Real-Time Data Graphs, or Real-Time Segments, you have to purchase the Sub-Second Real-Time Service Usage Add-On. The basic cost is unknown.
Real-time profiles - provides an option to maintain the profiles with real-time updates and functionalities. The basic cost is 750$ per 10,000 profiles.
Data Cloud One - increases the maximum Data Cloud instances connections. The cost is 60,000$ per additional instance connection.
Platform Encryption for Data Cloud - if you want to encrypt the Data Cloud data with additional customer-managed root keys, you have to purchase the Salesforce Shield (f.k.a. Platform Encryption) Add-On for your Data Cloud instance. The basic cost is unknown.
Private Connect – if you want to connect to your Data Cloud instance with a private connection (Snowflake and Redshift currently available), you have to purchase the Private Connect Add-On for your Data Cloud instance. The basic cost is 600$ per connection.
Data Masking - called sometimes Einstein GPT service add-on, provides the dynamic data masking and data tagging for structured data. The basic cost is unknown.
From September 4, 2025, the Segmentation and Activation add-on is no longer needed to access the segmentation and activation features. All Data Cloud licenses are now capable of use these features without any additional cost.
In terms of the licenses, all topics like data storage, admin and user account number, and so on look quite clear. But what about credits? There is not so much information about credits in the documentation or pricing details, nor in the Data Cloud demos. But it turns out that they will be crucial in your implementation and maintenance. Why?
What are Credits?
Credits in Data Cloud (a.k.a. CDP, a.k.a. Genie) are like coupons, that you spend to cover your Data Cloud usage bill. In other words – you buy Data Cloud Credits for your money and then you can use them to pay for importing data, exporting data, transforming data, profile unification, or segmentation and activation.
Salesforce Data Cloud is hosted on Amazon Web Services, where credits have the same role. So basically you pay Salesforce, who pays Amazon, for operations, that you make in your Data Cloud instance. 💁♂️
Salesforce merged the two types of Credits, that existed in Salesforce Data Cloud. Data Services Credits was a name for credits that are used for data processing (e.g. importing, exporting, transforming, unification). Segment and Activation Credits were used for data segmentation and activation (they were available as an add-on, not included in the basic package). Currently these two types are merged, but in the older instances you can find the deprecated Segment and Activation section in some places, e.g. in the Digital Wallet.
Credits usage per each activity
Now we dive into the more interesting stuff. Surfing through the official Data Cloud documentation it won’t be so easy to find the proper Credits usage calculation for each feature in the system. The two core sources for us will be the Data Cloud Billable Usage Types from the documentation and Multipliers for Data Cloud, which are not so easy to find on the website.
| Usage Type | Unit | Multiplier (Credits) |
|---|---|---|
| Batch Internal Data Pipeline | 1 Million Rows Processed | 0 |
| Streaming Internal Data Pipeline | 1 Million Rows Processed | 0 |
| Batch Data Pipeline | 1 Million Rows Processed | 2,000 |
| Streaming Data Pipeline | 1M Rows Processed | 5,000 |
| Batch Data Transforms | 1 Million Rows Processed | 400 |
| Streaming Data Transforms | 1M Rows Processed | 5,000 |
| Unstructured Data Processed | 1MB Processed | 60 |
| Data Federation or Sharing Rows Accessed | 1M Rows Accessed | 70 |
| Data Share Rows Shared (Data Out) | 1M Rows Shared | 800 |
| Batch Profile Unification | 1M Rows Processed | 100,000 |
| Sub-second Real-Time Events | 1M Events & API Calls Processed | 70,000 |
| Batch Calculated Insights | 1M Rows Processed | 15 |
| Streaming Calculated Insights | 1M Rows Processed | 800 |
| Inferences | 1M Inferences | 3500 |
| Data Queries | 1M Rows Processed | 2 |
| Streaming Actions (including lookups) | 1M Rows Processed | 800 |
| Segment Rows Processed | 1M Rows Processed | 20 |
| Batch activation | 1M Rows Processed | 10 |
| Streaming DMO Activation | 1M Rows Processed | 1600 |
Let’s start with a Multiplier explanation. This is nothing more than the amount of credits used per 1 million processed records. For example, if we have processed 500,000 records in Calculated Insights, we have used 15/2 = ~8 credits. Now, let’s talk about each of the types, following the billable usage types documentation.
The Internal Batch Data Pipeline represents the ingested data from Salesforce products (via Salesforce CRM connector, Marketing Cloud connector, Commerce Cloud connector, Marketing Cloud Personalization connector) to the Data Cloud. From the 13th of August 2025, the Internal Batch Data Pipeline is completely free.
The Internal Streaming Data Pipeline represents the ingested data from Salesforce products (via Salesforce CRM connector, Marketing Cloud connector, Commerce Cloud connector, Marketing Cloud Personalization connector) to the Data Cloud within the Streaming Data Streams. From the 13th of August 2025, the Streaming Data Pipeline is completely free.
The Batch Data Pipeline represents the ingested data through the Data Stream to the Data Cloud. With the multiplier set as 2000 credits per 1M rows, you should estimate how much data you will bring. There could be scenarios when starting ingested data won’t be a problem, but their rapid growth may be pushing usage to your license limit day by day.
The Streaming Data Pipeline represents the Streaming Data Streams and Streaming Data Transforms operations. Calculated in the same way as Batch Data, they are 2.5x more expensive, but they could process the data in near real-time.
The Batch Data Transforms represent the data processed within the Batch Data Transform functionality in the Data Cloud. Depending on the scenario, you will have to calculate the processed records from starting DLO/DMO and DLOs and DMOs added to the Transform. Batch Data Transforms are not so expensive, with 400 credits per 1M processed rows, but you will use them as a data deduplication and cleaning solution for all of your data (which could mean a lot of processed records).
The Streaming Data Transforms represent the data processed within the Streaming Data Transform functionality in the Data Cloud. Depending on the scenario, you will have to calculate the processed records from starting DLO/DMO and DLOs and DMOs added to the Transform. Streaming Data Transforms are used within Streaming Data, so they are more expensive than Batch Data Transforms. Costing 5000 credits per 1M processed rows, if you will use them as a data deduplication and cleaning solution for all of your data, they could be very expensive, but sometimes necessary.
The Unstructured Data Processed represents the unstructured data process (PDF, TXT, HTML files currently, audio and video files in the future). With the multiplier set as 60 Credits per 1 MB, it seems that this will be a widely used usage type in the future to boost the Agentforce and Einstein AI capabilities within TXT, HTML, and PDF documents. But it will be painful when it comes to the audio and video files, so be careful here.
The Data Federation refers to the records accessed within the Zero-ETL, also called No-Copy or BYOL connectors, currently supporting Amazon Redshift, Databricks, Google BigQuery, and Snowflake. They are a quick (real-time) alternative to the Batch and Streaming Data Pipeline, with a multiplier set as 70 Credits per 1M rows accessed. But rows accessed mean that they are not copying the data to the Data Cloud. You will pay only for the rows returned from the source, but you will pay for each time the Data Cloud will ask for these data. You should also know that you or your client will also pay for all of the requests from Data Cloud in the data source platform (e.g. query run in Databricks environment). If you want to use Accelerated Data Federation (with caching), you will also be billed for Batch Data Pipeline for storing the cached data in Data Cloud’s DLO.
The Sharing Rows Accessed refers to sharing the data to the external data platform and is calculated based on several rows queried from the external data lake’s request.
The Batch Profile Unification represents the unified source profile data. It is the most “expensive” task in the Data Cloud. It is also the most tricky one, with a not-so-clear definition of what 1 million processed rows mean and how many rows takes to unify one Profile. We will cover it in the next paragraph.
The Sub-second Real-Time Events refer to the usage of Web SDK or Mobile SDK event tracking through the sitemap, the feature well-known from Marketing Cloud Personalization, which could be implemented also in the Data Cloud. But it is very, very expensive. 70,000 Credits per 1M events (no matter if it is an event triggered by sitemap or API) is an incredible amount. For context, if we pay for these events with additional bought Service Credits, the current Marketing Cloud Personalization Growth license basic cost (108,000 USD) is the equivalent of ingesting around 155 million events (~12,9m per month) through Data Cloud Web SDK. So if you record more than 13m user events within Data Cloud Web SDK per month, you will pay more than the equivalent of a basic one-year Marketing Cloud Personalization license that has no strict event number limits.
The Batch Calculated Insights represent all records processed during building the CI (Calculated Insights). Note that we count records in all objects that we use for our query and it counts every time the CI runs. For example, with a multiplier of 15 credits, if we build Calculated Insight joining the first DMO (Data Model Object) with 2M records and the second DMO with 1M records, no matter how many records we finally got, we processed 3M records, so we used 45 credits. If we use this CI in the segment that is updated every day, we spend 45 credits every day.
The Streaming Calculated Insights are similar to basic Calculated Insights but are used for real-time data processing. Pretty expensive.
The Data Queries and Accelerated Data Queries represent the usage in the Data Transforms tool and are calculated on records processed. Accelerated Data Queries are used with Tableau or CRM Analytics. They are widely used in all of the internal and external API calls that requires the querying the data in Data Cloud. They are the cheapest operations in Data Cloud, so check if you can use them in your case, but be aware, that this solution can scale up quickly with more use cases being implemented.
Inferences are defined as any data output produced by AI model in Einstein Studio. For example: using AI in flow action (1 flow triggered = 1 inference), prediction job on data model (100 records = 100 inferences), generate text with LLM (1 text generated = 1 inference).
Data Share Rows Shared (Data Out) represents the data processed with Data Share functionality. The Changed type represents the new or changed records in the data share.
Streaming Actions represent the Data Actions activity in the Streaming Pipeline and Streaming Calculated Insights flow (real-time). Also not so cheap, but usually you will use them in pretty important use cases.
The Segment Rows Processed represents the number of rows processed to create the Segment. The catch here is the segment will count all of the rows processed from the DMOs that you get the data from. For example, if you use the data from two DMOs, 2M records each, you will process 4M records no matter the final segment population number. The more complex calculations come if you segment on an Individual and want to create the filter on a field from a related DMO, which is related to another DMO, which is related to the Individual, the more “nested” filter, the more records processed.
The Batch Activation represents the number of rows processed through the segment activation process. Same scenario as in Segment Rows Processed. Note that this is counted in the same way with or without related attributes.
The Streaming DMO Activation represents the number of rows processed through the Data Model Object Activation. Currently, it can be used only within Meta Conversion API platform connector.

Profile Unification Credits usage
Talking about Profile Unification, there are a lot of questions about how many of the Profiles can be processed with some amount of credits, especially in the free Data Cloud Instance. Some of the promoting materials were talking about 10,000 profiles in the Data Cloud Provisioning Package, which contains 250,000 Credits. With this information, Salesforce Ben estimated, that the one processed Unified Profile takes 25 credits.
25 credits is a very, very huge number. With official Credits add-on pricing set as 1000 USD per 100,000 credits, we can calculate that in this theory one Unified Profile will cost us 0.25 USD. Pretty much, right? With 10M credits in the Data Cloud Starter package, we would use all our credits if we unify only 400k Profiles. But this calculation is a sort of generalization. Why?
To go through this, we need to take a deep dive into the documentation and Salesforce nomenclature. Citing from official Docs:
Batch Profile Unification usage is calculated based on the number of source profiles processed by an identity resolution ruleset. After the first time a ruleset runs, only new or modified source profiles are counted. A source profile is an individual and their related records, such as contact points and party identifiers, which are included in the identity ruleset.
For example, modified means deleted profiles, or profiles marked as suppressed via Consent API preferences.
The key term here is a source profile. A source profile is a record with personal data that is processed by the Identity Resolution ruleset.
Let’s take an example. We have 500,000 user records ingested from Amazon S3 Connector, 700,000 user records from Salesforce CRM connector, and another 200,000 user records from Marketing Cloud connector, all ingested 1:1 to Individual and related Data Model Objects, e.g. Contact Point Email. Starting the unification process, we have 1,400,000 source profiles. After Unification, no matter if we finally got 1,400,000 Unified Profiles, 400,000 Unified Profiles, or 100,000 Unified Profiles, we used 140,000 credits.
Looks better, right? In this scenario, with the result of 400,000 Unified Profiles, we used only 0.35 credits (0.0035 USD) per Profile (and we used about 60% of our credits from the Data Cloud free license). Even if we add the cost of Data Stream ingestion (2800 credits), it is a cost of 0.357 credits (0.00357 USD) per Profile.
What is more, a source profile is a record with information from the Individual DMO and all related records, which includes Contact Point DMOs, Party identifiers, or related custom DMOs. Good information is that when we do the Profile Unification, we count only one processed record as a whole source profile instead of for example 3 records (when we have Individual, Contact Point Email, and Contact Point Address DMOs).
There is another side of the coin. We also count modifications, deletions, or suppression as processed records in Profile Unification. It means that every small change, no matter if we modify 1, 5, or 50 attributes in one record, even in the related DMO, will process the source profile once again in the next Identity Resolution run and will cost us 0.1 credit per modified source profile.

Data Cloud Sandbox credit usage
Sandbox environment in Data Cloud is available and recommended for every implementation, especially associated with Salesforce Dev Orgs. Data Cloud supports every sandbox type - Developer, Developer Pro, Partial Copy and Full Copy. They use only Note that this feature is still in development and new functionalities comes in every release.
Data Cloud Sandbox uses the same credit pool as the Production environment, but it is 20% cheaper:
| Usage Type | Unit | Sandbox Multiplier (Credits) |
|---|---|---|
| Batch Internal Data Pipeline | 1 Million Rows Processed | 0 |
| Streaming Internal Data Pipeline | 1 Million Rows Processed | 0 |
| Batch Data Pipeline | 1 Million Rows Processed | 1,600 |
| Streaming Data Pipeline | 1M Rows Processed | 4,000 |
| Batch Data Transforms | 1 Million Rows Processed | 3200 |
| Streaming Data Transforms | 1M Rows Processed | 4,000 |
| Unstructured Data Processed | 1MB Processed | 48 |
| Data Federation or Sharing Rows Accessed | 1M Rows Accessed | 56 |
| Data Share Rows Shared (Data Out) | 1M Rows Shared | 640 |
| Batch Profile Unification | 1M Rows Processed | 80,000 |
| Sub-second Real-Time Events | 1M Events & API Calls Processed | 56,000 |
| Batch Calculated Insights | 1M Rows Processed | 12 |
| Streaming Calculated Insights | 1M Rows Processed | 640 |
| Inferences | 1M Inferences | 2800 |
| Data Queries | 1M Rows Processed | 1.6 |
| Streaming Actions (including lookups) | 1M Rows Processed | 640 |
| Segment Rows Processed | 1M Rows Processed | 16 |
| Batch activation | 1M Rows Processed | 8 |
| Streaming DMO Activation | 1M Rows Processed | 1280 |
How do I check my Credit volume?
To check how many Credits you got with your license, you should first find out what license you bought (of course if you don’t remember or were not responsible for buying it). If you do not have access to the contract, you can check it in the Your Contracts section. Look for the Data Cloud named product. You can also do this in the Data Cloud Digital Wallet.
Data Cloud Digital Wallet
If you want to check how many credits you have left, you can use a new functionality called Data Cloud Digital Wallet.
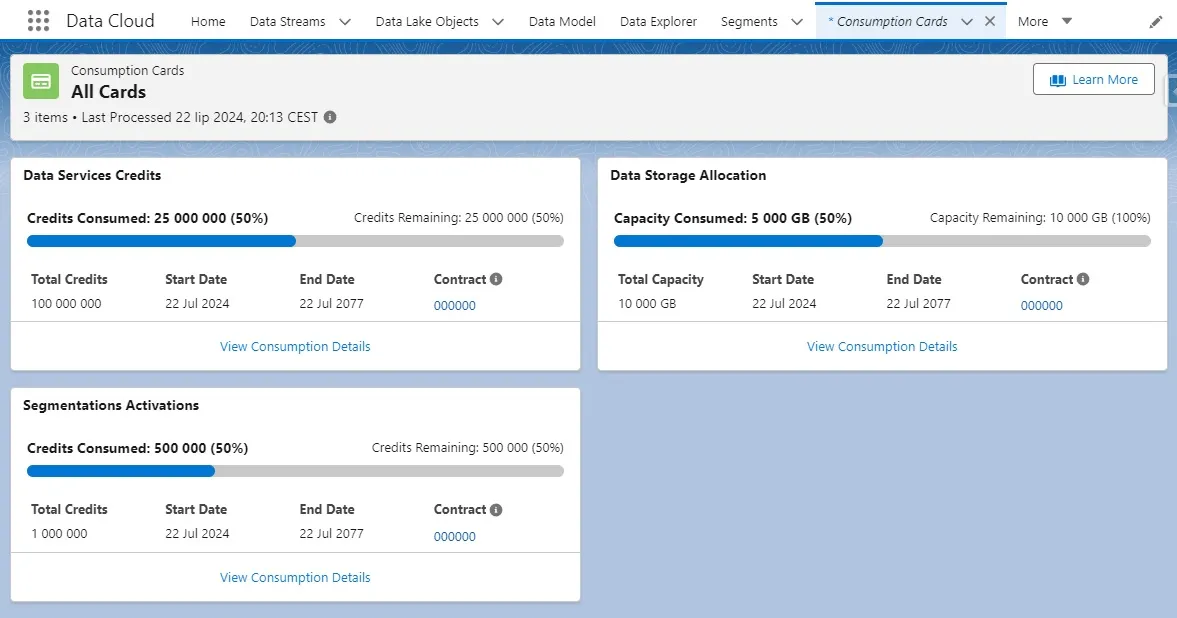
Data Cloud Digital Wallet is a new feature that shows the current Data Services Credits, Segment and Activation Credits, and Data Storage Allocation usage. You can view the consumption details within a period (Last 24 Hours, Last 7 Days, Last 30 Days, and Last 90 Days). The data refreshes hourly.
To access the Data Cloud Digital Wallet, simply type the “Consumption Cards” in the App Launcher. The other way is to go to the Your Account menu and look for Consumption Cards on the navigation bar or in the UI card next to Invoices.
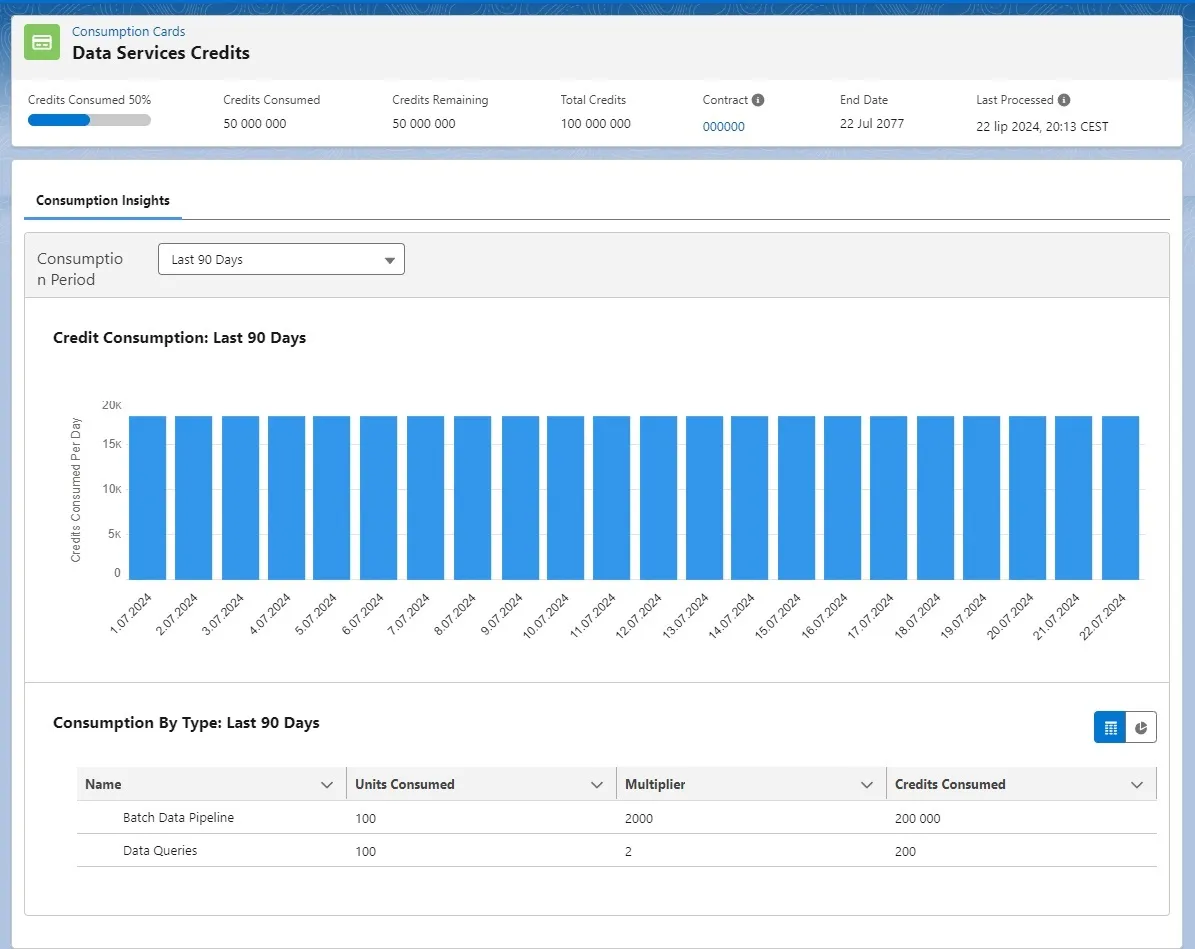
You can edit who can have access to the Digital Wallet and also export the Digital Wallet Data using the Digital Wallet DLOs. Refer to the documentation or check my article about Digital Wallet to find out more information.
How to save Credits?
There are many ways to reduce Credits usage, but the main answer to the question “how to save credits” is simple - REDUCE THE ROWS PROCESSED on each stage of the process. After reading this article, you probably have some ideas about how you could do this. But we can collect the most obvious and effective ways.
Before implementation
Make a good Discovery Phase
The first and probably most important tip. It can not only reduce used Credits but also speed up your implementation. Gather the functional requirements for the Data Cloud, get to know the data architecture in your company, and localize the necessary data sources that you need to fulfill your use cases.
Focus on use cases
Don’t immediately ingest all of the company’s data immediately to the Data Cloud. Try the use case approach - what data you will need to accomplish the goal? And then ingest just this. Then scale for next use cases.
Start small
Pick the simplest and least data-heavy use cases for the start. Even small implementation of Data Cloud could be time-consuming so focus on easy use cases that requires less data than more advanced scenarios. Then, after successful implementation, you can scale.
Ingestion
Reduce the frequency
Data Cloud can work in near real-time with Streaming Data solutions and regular data updates from Connectors. But every new data import, no matter if with an upsert or full refresh method, will use your credits. So check if your use case needs highly frequent data ingestion. The same tip can be used with segment and activation. Check how frequently the data should be updated in your scenario.
Note that Salesforce CRM Connector uses only automatic, 15-minute frequency, so if you have a lot of data processed many times on the same records throughout the day, the import could cost you additional credits.
Filter the data at the source side
To reduce processing of unnecessary rows, filter the data at the source side if possible. Data Cloud has the filtering option, but it will still process all of the records from the source and then filter the data. Use only the data that are necessary for your implementation. Check if you can get all data from less amount of data sources. Remember that more normalized data means more imported tables, which means more records processed.
Count processed records
Usually, if you have external Data Streams with Incremental Refresh, you should count the processed records, not the changed or added ones. Each time the process runs, Data Cloud will process all of the records in your data source and then decide which records should be changed. So if you have a data source with 1M rows, ingestion will process 1M rows, no matter if it changes only 10 or 100,000 records.
Get every needed attribute
Sometimes it is good to reduce the number of attributes that you ingest from data sources to Data Lake Objects (because if you import it, you will be able only to disable it, but not hide or delete it). But remember that after the first ingestion, if you would like to add another attribute, you will have to process all the records again.
Check the Zero-Copy option
Zero-Copy connectors can drastically reduce the ingestion credit usage. With a multiplier set as 70 credits per 1M processed rows they could be a cheap alternative for batch ingestion of a large number of rows. But remember that the zero-copy queries are also billed at the Cloud Provider’s end.
Prioritize the internal data pipeline if possible
If you can choose data from Salesforce products over external sources or APIs, go for it. With the internal data pipeline set as 500 credits per 1M rows for both Batch and Streaming ingestion, you can focus more on the use cases that need internal data at the beginning of implementation.
Split the Data Streams
Consider splitting the data streams for upserts and deletions if you want to ingest files or tables that are not updated frequently. If you have time-sensitive data that cannot be ingested in a streaming format.

Transform
Prepare the data on the source side
If possible, clean and prepare the data on the source side. Especially if you work with Snowflake, Big Query or other DMP/Warehouse tool that have the cleaning and transforming functionality.
Use Formula Fields
Formula Fields are a free option to create additional columns with specific data. Despite being restricted to specific connections and operators, sometimes they will allow you to avoid using Data Transforms.
Use incremental transforms
If you have a Data Transform that runs more often than 24 hours, you can use the Incremental Transform type to limit the records processed. After the first full run, for the next 24 hours, Incremental Data Transform will process only new or changed records in the target DLO or DMO. This can significantly reduce the credits used. Remember about limits in incremental transform.
Implement the deletion process
If your compliance rules allows to not store deleted users and related records, you can implement the deletion process that will wipe out this data from Data Cloud. This will result in reducing the rows processed for each of the “cleaned” DLO and DMO.
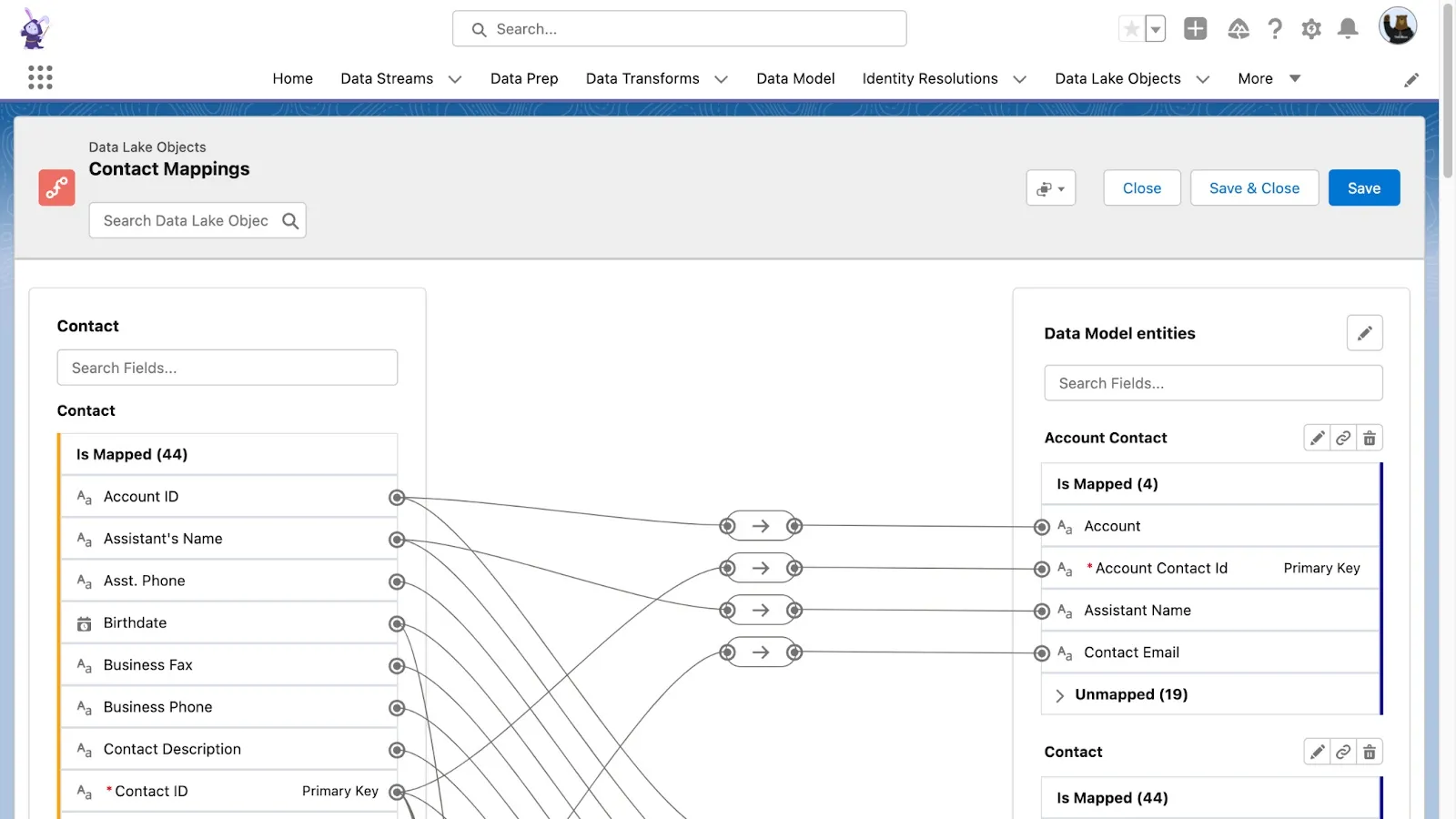
Mapping and Identity Resolution
Draft the mapping before ingestion
For some of the connectors, there is an option to do the “draft” mapping before ingesting the data. With the connector set up, you can create a Data Stream by adding all necessary headers, skipping the data ingestion for now. You can now map these headers, create relationships, check if the data model architecture is correct, and then ingest the data.
Divide the data to separate DMOs
You can split the huge tables or views into smaller pieces. For example, if you have data from several years, you can split it into separate tables or views with historic data and data from the last 2 years (or something similar, depending on your use cases). Then, creating separate DMOs for historic data and current data will allow you to segment and query only on the period that you are interested in, reducing the records processed. Especially if you use the Other data category, as the lookback window works only for the engagement data category, note that this approach has some limitations and implications.
Denormalize if possible
Maybe it’s not the best practice, but a cost-saving practice. Reduce the number of separate objects if you can. Each additional related object storing 1M rows will cost you an additional 1M processed rows in every query, every segment, and every activation that uses this additional related object.
Check if you need the Identity Resolution
Identity Resolution is the most expensive feature in the Salesforce Data Cloud. But you won’t use it in every implementation. If you know that the data is normalized, unique, and well-arranged, you can build a fully custom solution and/or skip the Unification process and work on defined relationships. It will be a more complicated, more technical, and not so easily scalable solution, but it can save you a huge amount of credits, which is crucial, especially in the free tier.
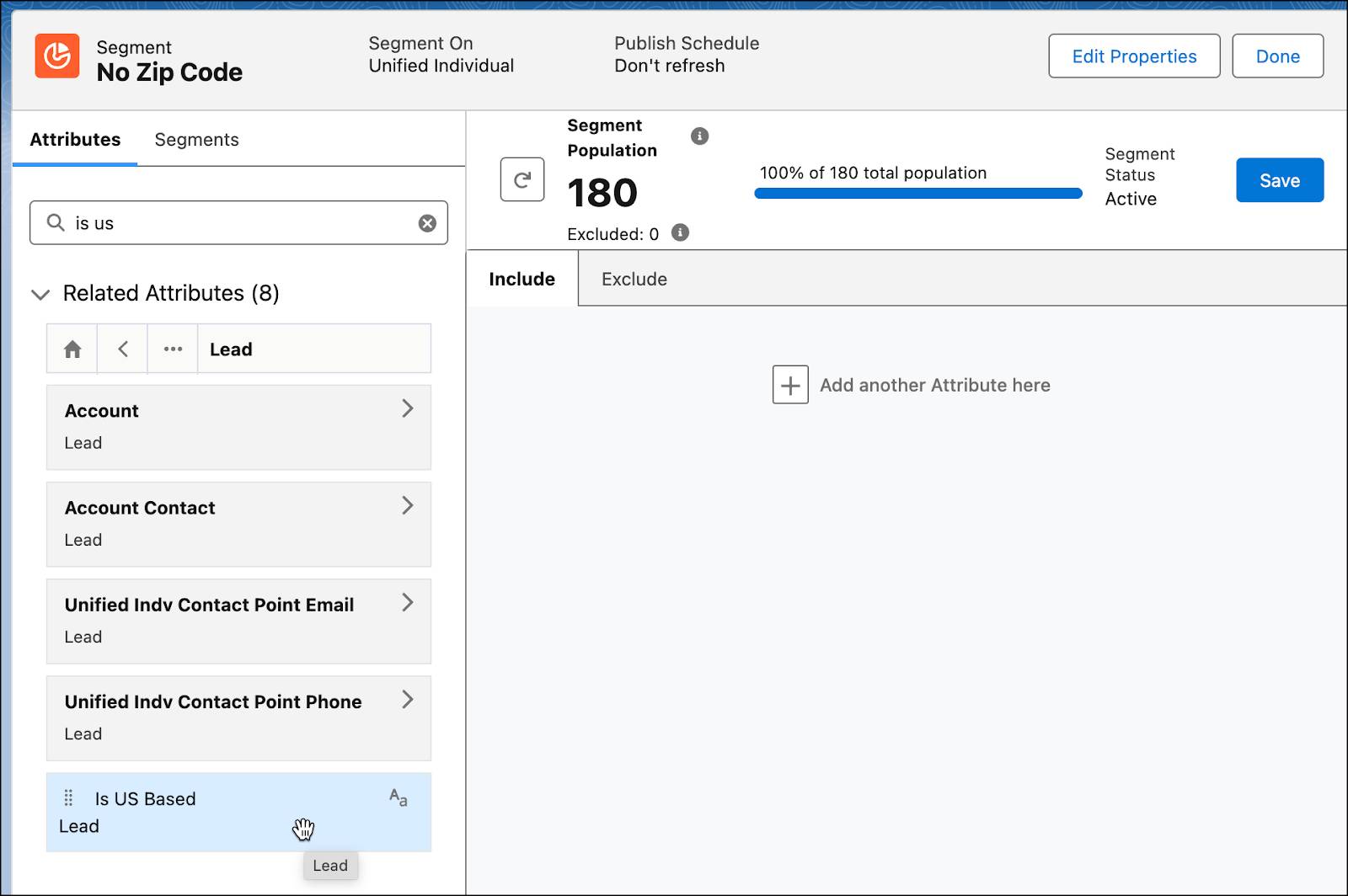
Segmentation and Activation
Reduce re-running in the editor
In the segment builder, each time you recalculate the population, rows will be processed. Try to do as few segment changes as possible to check the result.
Use Query Editor
If you know SQL well, you can easily recreate the segment logic in the Query Editor tool and check the output, or use the COUNT option to see the population size. This could be helpful if your segmentation and activation credit pool is very limited.
Narrow the segment with Calculated Insights
Using Calculated Insights for narrowing the audience, you can push the billing from segmentation and activation type to data service type. Batch Calculated Insights are cheap and can significantly reduce the number of processed rows in Segmentation and Activation.
Reuse the segments
You can use nested segments and reuse the segments that you have, instead of creating new ones that will process the data again. For example, you can create a wider segment with some specific rules and then build smaller segments on it, using the Segment Membership DMO.
Be careful
Note that every action in the Data Cloud costs you. Processing data in every ingestion, every Data Transform, every Calculated Insight, and every Segment will be paid. Remember that you can add the Data Streams and map the Data Lake Objects without starting the data ingestion. You should be careful, especially if there is still no easy way to find out how many Credits you spent for which operation.
Data Cloud is a powerful tool, with powerful features. Although it is in development (just check how many new options and fixes it got through the year), it can be used in a lot of use cases, especially focused on marketing automation solutions. With a nearly no-code approach, it seems to be an easy and friendly option to process and segment your data. Especially if there are a lot of rumors about moving the Marketing Cloud options into the Data Cloud.
But there are some things that we should be careful about. I hope that this article will make it clear what Data Cloud billing looks like, how to calculate Credit usage, and how to become more aware while working with this tool.