 We are setting up the Data Cloud, ingesting data, mapping DMOs, building segments and activations - cool, but what’s actually happening beneath the familiar interface?
We are setting up the Data Cloud, ingesting data, mapping DMOs, building segments and activations - cool, but what’s actually happening beneath the familiar interface?
After several implementation projects within Data Cloud, I kept thinking about this - what is actually happening, when we work with this new tool. Maybe not because I wanted to build my own Data Cloud, as it will take about 100 years of one-person work as LLM estimated. Maybe.
Table of Contents
- Why Data Cloud architecture matters
- AWS Infrastructure Stack
- Apache Iceberg Foundation
- Query Engines
- Identity Resolution with Lucene
- Today’s Data Cloud infrastructure landscape
Why Data Cloud architecture matters
First, Data Cloud operates on fundamentally different principles than traditional Salesforce CRM. It’s not monolithic, but a hybrid infrastructure, based on microservices, built to handle billions of records per instance - with the upcoming AI capabilities. The architectural difference directly translates to what you see and what you can do in the interface. You have a different data model and a different approach to creating faster data queries (e.g., using Data Graphs).
Secondly, Data Cloud evolves so rapidly that I barely keep up with all of the changes. Understanding the underlying architecture helps predict where future functionalities are heading. This knowledge can also give an advantage in solution design and the discovery phase.
Of course, I could not describe the Data Cloud architecture with 100% accuracy, as I am not the Big Data Architect, as the whole solution is huge, and this tool is not open-source software. But I will try to do so, with some clues that we have from Salesforce itself, from their documentation, and the engineer’s blog.
So let’s dive deep.
AWS Infrastructure Stack
Amazon AWS provides the cloud foundation for Data Cloud. Amazon not only provides the physical infrastructure, regions, and availability zones, but also provides a container, storage, processing, and application layers.
Previously, Data Cloud used Amazon EC2 (Elastic Compute Cloud), which provided virtual machines in the cloud. The whole process of managing virtual machines was handled directly by the Salesforce engineering teams, requiring configuration of servers, systems, applications, and scaling. With the increase in demand, this meant a lot of additional work (and money 💵). That’s why Salesforce decided to implement the Kubernetes infrastructure. This provided 54% compute cost reduction, which translates directly to the potential margin for Salesforce (and maybe lower credit pricing in the future 👀).
 Dashboard showcasing cost reduction after migration to Kubernetes, Source: engineering.salesforce.com
Dashboard showcasing cost reduction after migration to Kubernetes, Source: engineering.salesforce.com
Today, Data Cloud operates on:
- Amazon S3 storage, which serves as the independent storage layer where all customer data lives permanently in Apache Parquet format with Iceberg metadata files.
- Hyperforce provides data residency control - the customer can choose specific regions where the data is stored to meet compliance requirements like GDPR.
- Amazon EKS (Elastic Kubernetes Service) service, which manages the Kubernetes control plane, while the Kubernetes Resource Controller (KRC) extension integrates Kubernetes with the Salesforce platform. Kubernetes is essentially a container management system that automatically decides where to run applications, how to scale them, and how they communicate with each other, to optimize computing resource allocation.
- Amazon EMR (Elastic MapReduce) infrastructure, which provides the managed big data platform that hosts the Spark, Trino and Hyper. Despite its “MapReduce” name, EMR now primarily serves as the infrastructure for Spark-based distributed processing.
When we create a segment, Kubernetes microservices coordinate with Amazon EMR and Spark clusters to process data from S3, with Kubernetes and KRC scaling the resource allocation needed to perform the task.
Apache Iceberg Foundation
Currently, when we work with Data Cloud, we are interacting with Apache Iceberg - but this was not always the case. Data Cloud grows rapidly not only in terms of functionalities that we see, but also in terms of infrastructure, which handles our queries.
Why Apache Hive was not enough
First versions of Data Cloud, formerly known as Salesforce Customer Data Platform, originally ran on a Hive and Metastore based data lake architecture. Hive is a SQL-like query engine that translates SQL Queries into MapReduce jobs (allowing them to split data into chunks and process them in parallel across multiple nodes) to run on the Hadoop clusters. The Metastore is a relational database (usually PostgreSQL or MySQL, or similar) that also stores metadata about tables, like schema definitions, partition locations, file paths, and table properties.
This stack worked fine for a moderate scale, when the Data Cloud was mainly the Customer Data Platform for the Marketing Cloud stack, and was not so popular. But when the product grew, with table count reaching millions, this architecture became a bottleneck, probably for several reasons:
- The batch-oriented MapReduce jobs used on a huge scale became a high-latency solution, which decreased performance and made it impossible to perform real-time data operations.
- The single Hive Metastore database became a single point of failure. Every query within millions of tables required Metastore lookups.
- When the schema changed, Apache Hive had limited evolution capabilities - while adding columns was straightforward, renaming fields or changing data types often meant reprocessing entire datasets
- Hive had a huge ACID (Atomicity, Consistency, Isolation, Durability) Transactions overhead - based on the delta files and the manual merges (so-called compactions) with base files, it required a lot of effort to maintain the correct structure of data in millions of tables.
The Salesforce engineering team looked for an alternative that would allow them to build bigger, more flexible infrastructure. And the answer was Apache Iceberg.
 Lakehouse Infrastructure, source: engineering.salesforce.com
Lakehouse Infrastructure, source: engineering.salesforce.com
Apache Iceberg Three Layers Architecture
Apache Iceberg solved the Hive problems through a completely different approach in terms of ACID transactions handling and also in terms of the whole infrastructure. It is based on three layers:
- Catalog Layer - it replaces the single Hive database with multiple catalog types, like AWS Glue, Hive Metastore (for compatibility), REST APIs, and even simple file-based catalogs. With a change in a DMO, Catalog Layer creates a new metadata pointer in milliseconds - no more overnight schema migrations that used to plague Hive-based systems.
- Metadata Layer - Iceberg creates more detailed metadata files alongside the data, covering schema versions, snapshots, partition information, and file-level statistics. Metadata files are stored in JSON format, while manifest files and manifest lists use Avro format for fast reading.
- Data Layer - actual Parquet files with our data. Without any directory structures, just plain files in the lakehouse with a metadata layer that handles the organization process.
When we change a DMO schema in the Data Cloud, Iceberg can simply create new metadata pointing to the updated table structure - and the whole ACID transaction is covered. Nearly 90% of all queries use the cached metadata, which boosts the performance. Iceberg allows Salesforce to process 22 trillion records quarterly across more than 4 million tables and 50 petabytes of data. The company is ready to scale 10x or even 100x in the next years. This Iceberg foundation operates on a microservices architecture, running three specialized query engines.
Query Engines
Instead of MapReduce jobs used with Hive, Iceberg works with three query engines:
- Spark - handles both heavy batch processing and real-time streaming operations through Structured Streaming.
- Trino - formerly called Presto, provides fast interactive queries across data sources.
- Hyper - Tableau’s high-performance query engine that provides fast analytical processing.
Typically, when we run segmentation queries, the metadata layer tells Spark exactly which files contain relevant data. If we ingest the streaming data, Data Cloud uses Spark Structured Streaming. When we use the enrichments in the CRM, Trino can quickly query the needed data. When we create the reports, the Hyper handles the query operations.
Spark
Apache Spark is a distributed computing engine, designed for processing large datasets. Spark operates by splitting data and computations across multiple worker nodes that can process data in parallel, which reduces the processing time. Unlike earlier big data frameworks used in Data Cloud, Spark does not rely so heavily on disk storage and keeps the intermediate results in memory whenever possible, making the operations faster.
In Data Cloud’s architecture, Spark runs on Amazon EMR clusters and serves as the primary processing engine alongside Trino and Hyper, but with the broadest responsibility scope. It bridges storage with user operations made in UI, handling the distributed processing of trillions of records daily (while Kubernetes manages the underlying infrastructure scaling).
 Spark use in segmentation process, source: engineering.salesforce.com
Spark use in segmentation process, source: engineering.salesforce.com
Spark is used for building Calculated Insights - there is an option to use the Spark SQL statements. We can also see how the Spark works within Segmentation and Activation in the Data Cloud. In segmentation, Spark processes the queries that extract specific audiences, based on the filter criteria for a specific segment:
- After the segment creation request, the CRUD Job definition is sent to the Job Orchestration Service. We don’t know if the Job Orchestration Service (also called Dynamic Processing Controller) in Data Cloud is a custom-made microservice or if it is managed by Apache Airflow. We do know that Airflow was used to migrate the data from Datorama to Data Cloud.
- The Job Controller in the Job Orchestration Service generates a job definition and stores the config.
- The Job Orchestration Service submits a task to the AWS EMR Cluster, which runs the new Spark Job.
- Spark processes the segmentation query against DMO data. SparkMetricsListener and QueryExecutionListener capture detailed performance metrics.
- Results are materialized as the Segment Membership DMOs (Latest Membership DMO and History Membership DMO).
- Job Telemetry gets the Spark Job results and metrics and processes, stores them, and sends them to the monitoring system, probably Splunk
- UI displays completed segment with member count and status.
 Spark use in the activation process, source: engineering.salesforce.com
Spark use in the activation process, source: engineering.salesforce.com
The same goes for the activation phase. With Spark, Data Cloud can enrich segmented data by joining other DMOs to provide additional attributes. The data is prepared by Spark DistCp (distributed copy) tool, which copies and writes the data to a file:
- Activation Engine sends the Job to the Dynamic Processing Controller (Job Orchestration Service).
- Dynamic Processing Controller submits the task to the AWS EMR Cluster, which once again runs the new Spark Job.
- Spark performs joins and gathers the necessary attributes like purchase history and contact points.
- Spark DistCp gets the data files from S3 storage (via DLOs via DMOs), then writes the files to the Squid Proxy server (open-source caching server).
- Finally, the Squid Proxy sends the data via the Activation Target definition to the target system.
Following the Agentforce launch, Salesforce faced a 3x growth in data ingestion demands. They used the Spark Streaming processing component and optimized their streaming architecture by moving from long-running Spark streaming jobs for each tenant to an on-demand model where jobs are only initiated when new data is available. This architectural change cut the cluster total spend (CTS) by almost 50%.
Trino
Trino is a distributed SQL query engine designed for fast, interactive analytics on large datasets. The key to Trino’s speed lies in its in-memory processing model - unlike batch processing systems, Trino streams results back to users as soon as they’re available rather than waiting for job completion.
Trino was widely used in the Salesforce Datorama (also called Marketing Cloud Intelligence). In Data Cloud’s architecture, Trino serves as the engine for interactive and exploratory segmentation queries. When we want to see the data in Data Explorer or calculate the segment population, the system routes these requests to Trino rather than Spark. Trino excels at this use case because it can return results very quickly.
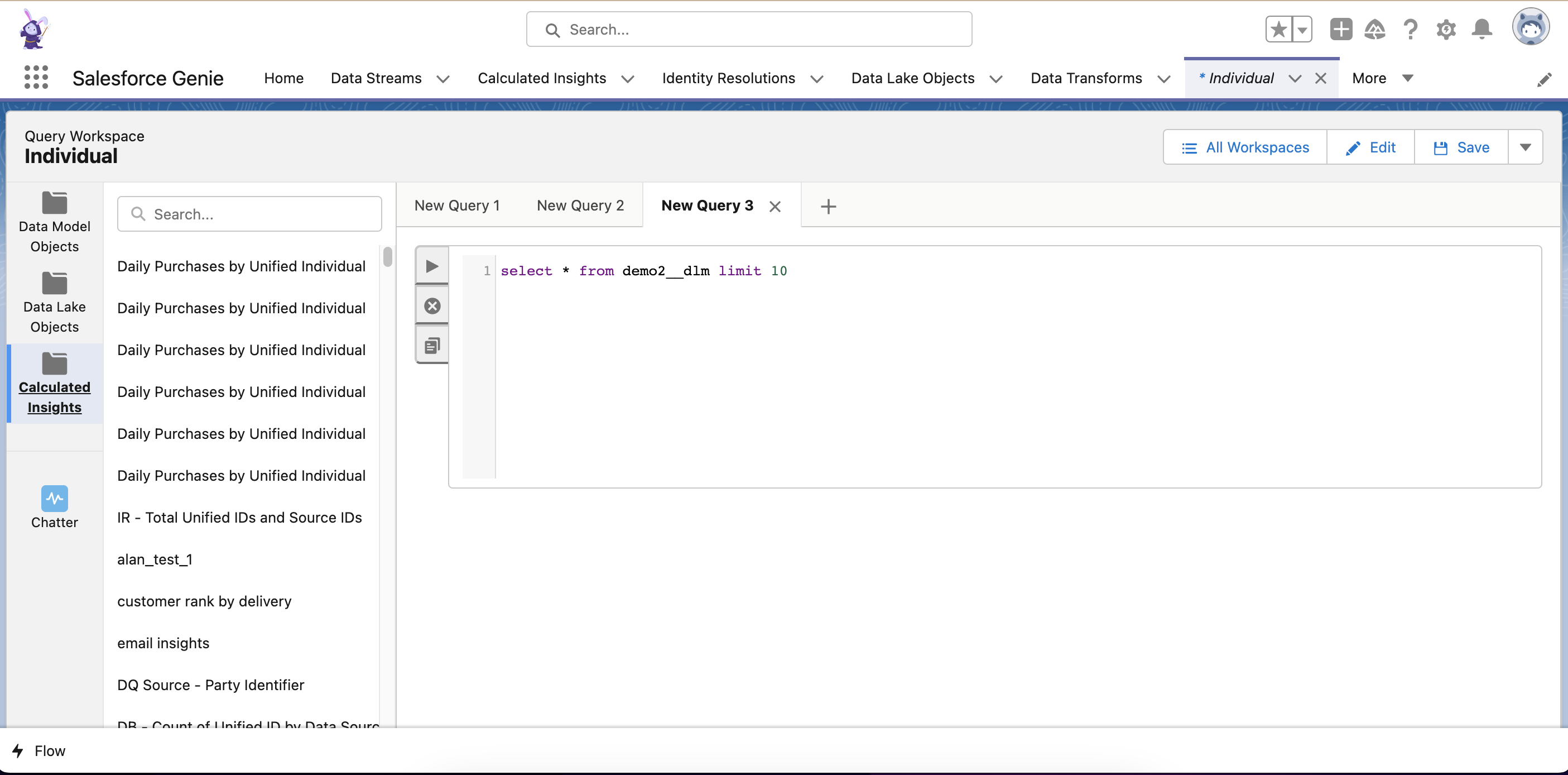 Trino is used to handle the queries built with Query Editor, source: appexchange.salesforce.com
Trino is used to handle the queries built with Query Editor, source: appexchange.salesforce.com
Currently, Trino handles the queries made in Query Editor. That’s why there are different SQL statements available in Query Editor and in Calculated Insights. It works well for quick data exploration tasks, but comes with some limits - in this case, the result will contain only 1,000 rows.
Trino was also used in the Query API and AI functionalities. The system based on Trino was prepared for handling 50 columns, 20 million rows, with 5000 unique values per column. But it was not enough. In the backend, Trino is widely used for insights on CPU utilization, memory usage, and request rates. Salesforce needed something faster and bigger.
Hyper
That’s why the last query engine entered the stack. Hyper is Tableau’s in-memory data engine technology optimized for fast data ingests and analytical query processing on large or complex data sets. It is specifically optimized for complex analytical queries and reporting workloads that require sophisticated aggregations, calculations, and visualizations.
Hyper uses an in-memory columnar architecture for OLAP analytical processing, not transactional operations. Unlike Trino’s focus on interactive data exploration or Spark’s batch processing capabilities, Hyper is specifically tuned for the types of complex analytical computations, such as dashboards, advanced analytics, and also - AI models.
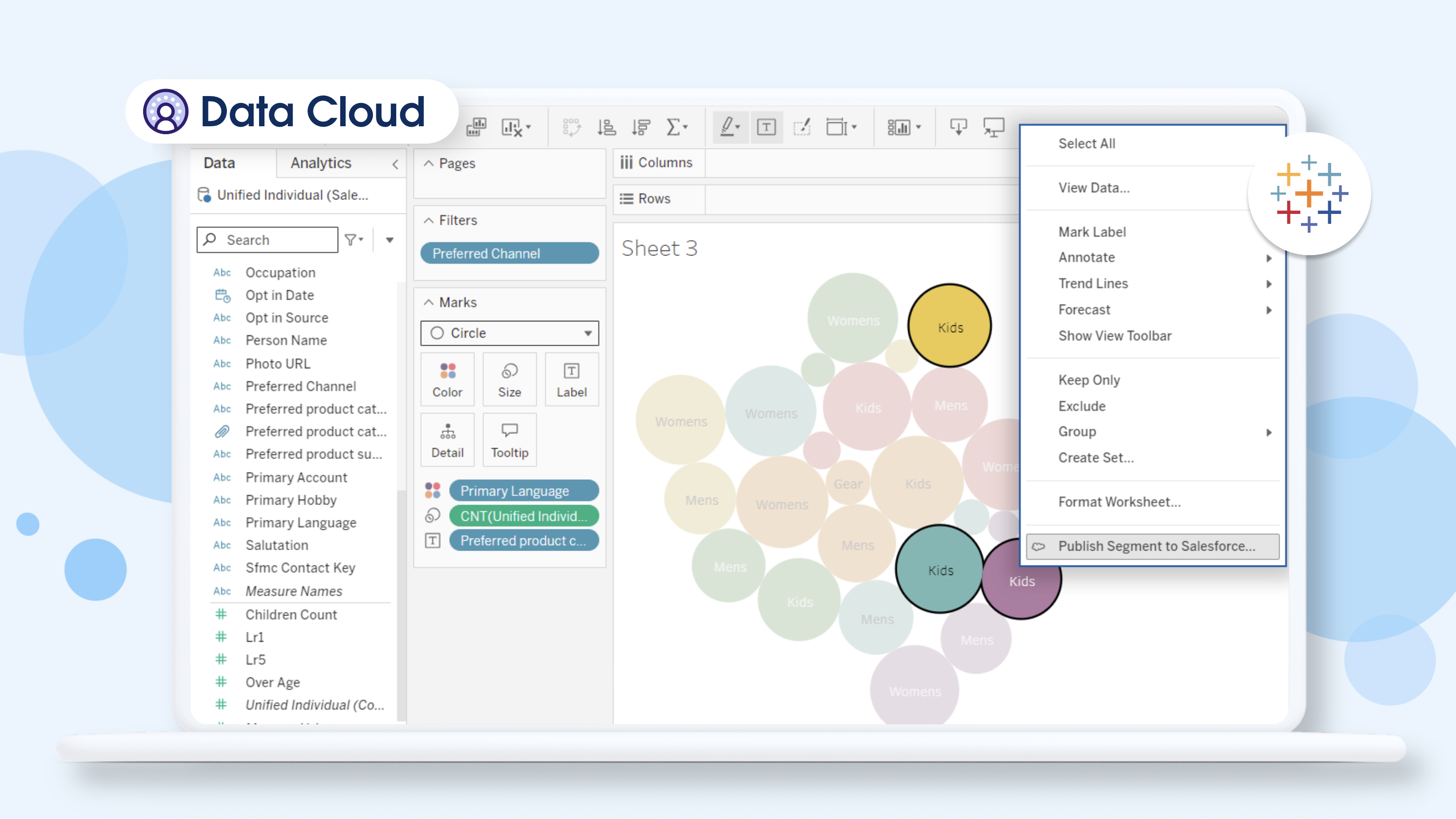 Hyper is used to build the visualizations in Tableau on Data Cloud data, source: tableau.com
Hyper is used to build the visualizations in Tableau on Data Cloud data, source: tableau.com
In Data Cloud’s architecture, Hyper serves multiple critical functions. As one of the fastest engines on the market, it is perfect for heavy-load, real-time tasks like regression and classification models used in Einstein and Agentforce functionalities - upgrading from Trino to Hyper improved the data read speed and query reliability. New engine provided the speed to operate on 300 columns, 20 mln rows, and 10k unique values per column. It can also process up to 500 million rows of data.
Hyper powers the Tableau to Data Cloud connector via the Hyper API, and it is also integrated into the newest Query API V3 (Query Connect API), providing no record limit and a significant performance increase in comparison with legacy Query API v2, which was handled on Trino.
From raw data to virtual views
With the data engines explained, we can better define the layers of Data Objects that are the foundation of the “visible part” of the Data Cloud. The journey from raw customer data to actionable insights follows a structured, three-stage pipeline built on the Iceberg and AWS foundation we’ve described. This is called a medallion architecture and is widely used in the Data Lakehouses.
Data Source Objects (DSO) serve as temporary staging areas where incoming data first arrives in its native, unprocessed format. When you upload a customer file or connect a new data source, the raw data initially lands in a DSO - think of it as a temporary holding area where data waits before any transformations occur. DSOs are not visible in the user’s interface.
Data Lake Objects (DLO) represent the persistent storage layer where your data actually lives as physical Parquet files in Amazon S3, organized as Iceberg tables. Once data moves from DSOs to DLOs, it gets cleaned, structured to match the Iceberg format, and permanently stored in the lakehouse architecture. This is the last step where the data is stored “physically” in the tables.
Data Model Objects (DMO) are the virtual views that provide a business-friendly interface to the underlying DLO data. Crucially, DMOs don’t store any data themselves - they’re logical mappings that present data from one or more DLOs in a standardized format. When you query an “Individual” DMO for customer segmentation, you’re actually accessing data from multiple DLO tables through this virtual layer, which explains why DMO queries can be fast (leveraging the 90% metadata cache hit rate) while remaining current with the latest data. That’s also the reason why the mapping is a no-cost operation in the Data Cloud.
Calculated Insights Objects (CIO) are the materialized views that store calculated measures built with Calculated Insights functionality. Based on their scheduled batch behavior, CIOs likely function as materialized views rather than pure virtual layers. The real-time calculated insights probably work more as the reference/virtual views, calculated by Hyper or Trino for real-time usage across other real-time Data Cloud functionalities.
And what about the Unified Data Model Objects? They are complex virtual views, with a materialized infrastructure under the hood. To explain this further, we have to see how Identity Resolution is processed.
Identity Resolution with Lucene
Identity Resolution is another activity handled with Spark. Initially, the Identity Resolution was run with the ElasticSearch service. The process requires a lot of computing power (and a lot of credits) due to functionality called fuzzy matching. When we match the records on exact rules, the job is easy, but when we want to use the fuzzy name matching, the probabilistic scoring enters the chat.
The complexity of fuzzy matching is significant - unlike deterministic matching, which compares exact values, fuzzy logic evaluates non-identical values using probabilistic scoring, leading to a much larger pool of potential matches. For example, the system must recognize that “Mr. John Smith” and “J. Smith” refer to the same person, or that “Susan” and “Sue” represent variations of the same name.
 Fuzzy matching logic with creation of hash buckets, source: engineering.salesforce.com
Fuzzy matching logic with creation of hash buckets, source: engineering.salesforce.com
When the source profiles in tests exceeded 50 million records, the performance issues began. ElasticSearch became a bottleneck, with ” index creation turned into a significant bottleneck, and high-concurrency queries, especially under heavy load, led to contention and performance degradation”. That’s why the Salesforce team went one layer of abstraction down and used the library that ElasticSearch is based on - Lucene.
By reducing the redundancy - as Data Cloud already uses Spark nodes for distributed computing -Salesforce could run Lucene directly on each Spark worker node. This architectural change eliminated the HTTP/REST API overhead, JSON parsing, cluster management, and network communication that ElasticSearch required.
The results were dramatic: the system scaled from handling 50 million to 2 billion source records in production-scale testing, with each Spark worker maintaining its own local Lucene index for fast, independent candidate retrieval during the identity resolution process. Now, the Identity Resolution can handle massive scale while maintaining stable performance even under extreme concurrency.
Today’s Data Cloud infrastructure landscape
The architecture of Data Cloud is definitely sophisticated. The infrastructure of Data Cloud rests on AWS with Kubernetes orchestration and Hyperforce, while Apache Iceberg provides the data lake foundation. Three data engines handle different workloads: Spark manages processing, Trino provides fast interactive exploration of data, and Hyper powers complex computations for AI functionalities and data visualization:
| Type | Technology | Data Cloud Areas | Primary Function |
|---|---|---|---|
| Cloud Infrastructure | Amazon S3 | Storage | Persistent data storage in Parquet format |
| Hyperforce | Platform | Data residency control and compliance | |
| Amazon EKS | Compute | Kubernetes cluster management | |
| Kubernetes Resource Controller (KRC) | Compute | Salesforce-Kubernetes integration | |
| Amazon EMR | Compute | Big data processing platform | |
| Data Foundation | Apache Iceberg | Storage/Metadata | ACID transactions, metadata management |
| Apache Parquet | Storage | Columnar data file format | |
| Query Engines | Spark | Segmentation, Activation, Identity Resolution | Batch processing, streaming, distributed computing |
| Trino | Data Explorer, Query API v2 | Interactive queries, data exploration | |
| Hyper | Analytics, AI Models, Query Connection API | Complex analytical processing | |
| Search & Identity | Lucene | Identity Resolution | Fuzzy matching, candidate retrieval |
| ElasticSearch | Identity Resolution (legacy) | Previously used for fuzzy matching | |
| Orchestration | Dynamic Processing Controller (DPC) | Job Management | Job orchestration and resource management |
The architecture evolved with the product. From the Hive to the more advanced Spark, and from ElasticSearch to direct Lucene integration across Spark nodes. The acquisition of Tableau allowed the transition from Trino to one of the quickest data engines in the market. The use of Kubernetes instead of plain EC2 virtual machines provided a significant reduction in computing resource allocation.
And more to come, with Agentforce, RAG, and planned features, the infrastructure will grow with the Data Cloud.
Sources:
- The Salesforce Platform - Transformed for Tomorrow
- Inside Data Cloud’s Open Lakehouse: Powered by Apache Iceberg
- How Data Cloud Scales Massive Data and Slashes Processing Bottlenecks
- How Data Cloud Processes One Quadrillion Records Monthly
- Data Cloud’s New High-Throughput, Low-Latency Service for Agentforce
- Scaling Identity Resolution with Lucene, Spark, and Fuzzy Matching
- Big Data Processing: Driving Data Migration for Salesforce Data Cloud
- Data Cloud Migrates From Amazon EC2 to Kubernetes in 6 Months
- Bridging Natural Language and SQL with Generative AI
- How to ETL at Petabyte-Scale with Trino - Salesforce Engineering Blog
- Big Data, Big Decisions: Finding the Right Technology for Interactive Analytics at Salesforce - Salesforce Engineering Blog
- Data Cloud and Tableau Use Cases
- ClickBench Benchmark
- Aggregatable Metric Considerations